
Healthcare companies have three overarching goals: improve health, enhance member and provider experience, and appropriately reduce total cost of care.
Each stakeholder has objectives that contribute to these overarching goals.

Healthcare companies also seek to:
- Manage their own data assets to drive insights and actions
- Optimize operational efficiencies
- Improve workflow intelligence
- Enhance provider and member experience
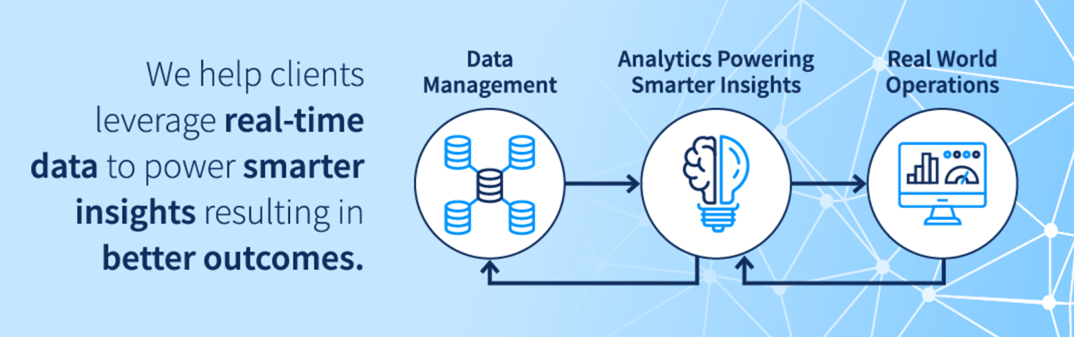
Data and analytics play a significant role in achieving these goals and objectives
EXL HEALTH DATA & ANALYTICS
At EXL Health, human ingenuity is the foundation from which we solve your complex problems. We combine data and analytics, cutting-edge tools and technology, and our domain expertise to drive innovation and informed decision making.
Areas of Expertise
- Market Expansion
- Provider & Network Analytics
- Customer Acquisition
- Population Health Analytics
- Risk Adjustment & Quality
- Member & Provider 360o
- Telehealth Analytics
- Social Determinants of Health (SDoH)Analytics
- Total Cost of Care Analytics
- Member/Patient Engagement
- Digital Enablement
- Data Management Services
- Payment Analytics
- Real World Insights
- Supply Chain Optimization
- Value-Based Contract Performance

Our Solutions and Services
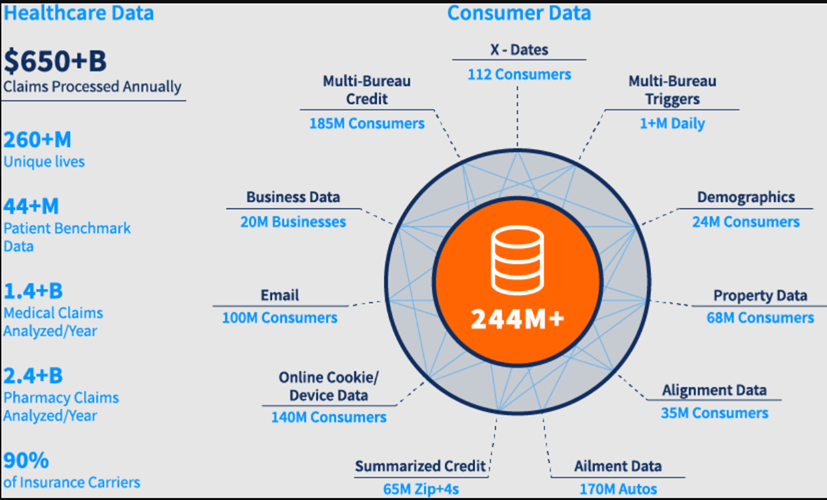
Curated Data Assets & Benchmarks
We enable actionable insights by leveraging and enriching our data assets that span across Commercial, Medicare and Medicaid populations, as well as augmenting the data with your own or a desired third-party's data sets.
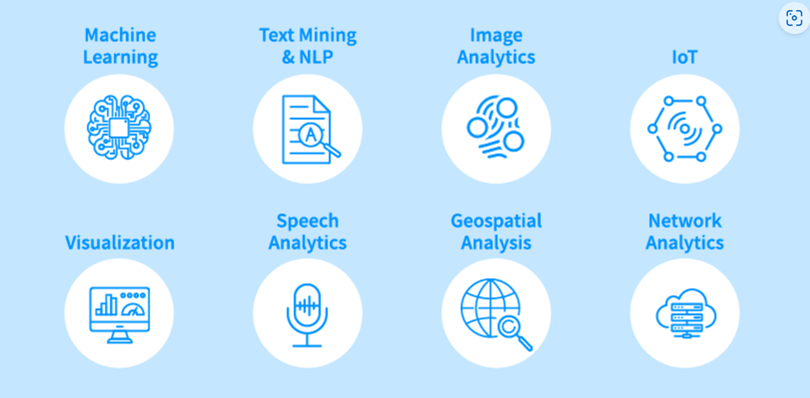
Delivering Better Outcomes Through Cutting-Edge Tools and Advanced Analytics
We leverage advanced analytics and digital technologies to drive smarter outcomes while improving provider and consumer experiences.
DIGITAL TECHNOLOGIES
Health Risk Scores
SDoH
lntervenability Score**
lmpactability Score*
Mortality Score
Claims Fraud Score
Patient Personas
Behavioral Health
Healthcare Data Management Services
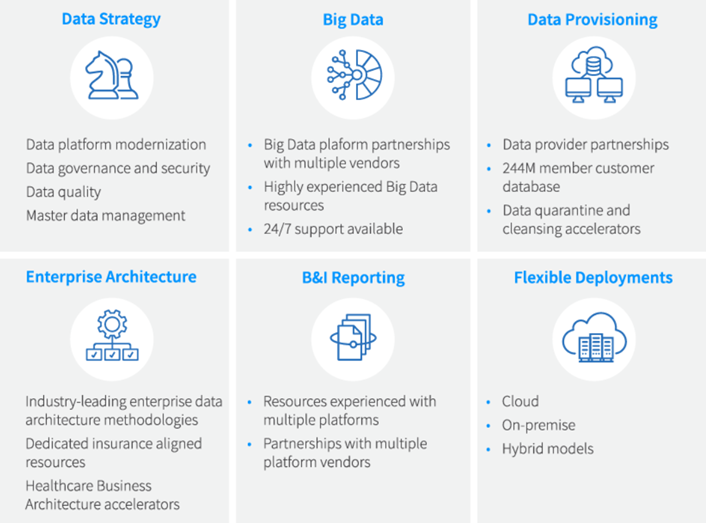
To make sense of your data, we help you develop a data strategy, establish governance rules to ensure data integrity, institute tool-agnostic data management capabilities and build an enterprise architecture that will transform your disparate data into a trusted, strategic asset.
Technology Platforms and Tools
We offer proprietary technology platforms and application modules, developed by healthcare industry thought leaders and subject matter experts that will accelerate your transformation.

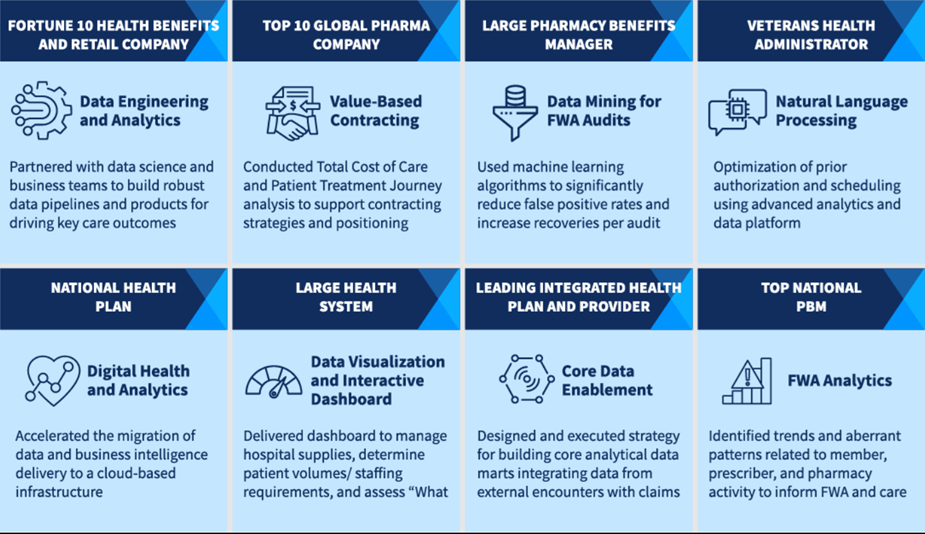
Proven Outcomes: Human Ingenuity at Work
Here are just a few examples of how our talent combines data, analytics, technology, and our domain expertise to deliver value to various healthcare stakeholders.
"This EXL Health Cost of Care platform is amazing and provides my team with the local level patient insights to help inform our Payer Marketing plans. The dashboard enables me to define custom patient cohorts for metric comparisons, and the charts & maps show clearly where to focus our attention."
Payer Marketing Lead Mid-Tier Pharmaceutical Client
Why Partner With EXL Health?
- Our diverse, global resources and delivery models allow us to provide capacity on demand, on- and off-shore
- Our practical experience provides us with unique perspectives, knowledge and applied learnings across the healthcare continuum, offering timely insights to complex challenges.
- Our cross-market expertise – Fully- and Self-insured Commercial segments, Medicare Advantage, Managed Medicaid, Health Information Exchanges – allows us to drive relevant, member and patient-centric insights, recommendations and outcomes.
- Our innovation is “always on,” whether it’s developing more efficient processes or finding and leveraging new data assets, new technologies, new analytics methodologies and techniques.