
EXL estimates the average fraud, waste, and abuse (FWA) rate hovers around 1 – 1.5% in the United States across most claims volumes.
Fraud is both an ever-present threat and growing opportunity for insurers who haven’t yet shifted to a data-driven detection model. EXL estimates the average fraud, waste, and abuse (FWA) rate hovers around 1 – 1.5% in the United States across most claims volumes. Yet, despite potential indemnity cost savings in the millions, fraud detection has been notoriously difficult for insurers to track.
Carriers face two main difficulties: a relatively small representation of known fraudulent customers, and a diversity of fraudulent behavior patterns.
Criminals, it turns out, are quite creative when it comes to evading identification. The solution lies in turning the problem on its head. Instead of identifying discreet patterns of potential fraud, organizations should identify fraudsters more generally, then work to minimize or remove falsely identified customers
Introduction
A carrier will process several hundred thousand legitimate claims, and only a handful of fraudulent ones. Yet, these fraudulent claims impact both the carrier as well as the insurance ecosystem as a whole – from those evaluating insurance products to current customers to specialists processing claims. Carriers are justified in their desire to root out fraud, waste, and abuse as these claims cost insurers an estimated $40 billion per year. The US Federal Bureau of Investigation estimates non-health insurance fraud costs the average U.S. family between $400 and $700 per year, by way of increased premiums.
Traditional fraud detection methods
Most efforts to detect and confirm FWA are reactive, meaning an investigation occurs after fraudulent claims payments have been processed. Fraud investigations can be grueling, and can take months, or even years, to complete. Even with enough evidence for prosecution, recovering payments is an arduous task.
In general, it’s a costly process. More often than not, perpetrators get away with committing fraud, as companies refrain from investigating paid claims, even with strong evidence of criminal activity. Together, these factors present a clear need for predictive modeling, one that identifies potential fraudulent activity early in the claims lifecycle. Moreover, these challenges emphasize the value of machine-learning techniques that continuously refine risk detection as the model is used (i.e., the longer the model is in place detecting FWA, the better it becomes at serving this purpose).
Use of predictive modeling
When we examine fraud patterns, we notice dishonest customers don’t always start that way. For example, a longterm care (LTC) claimant often submits legitimate claims for 2+ years before attempting fraud. Carriers must carefully parse out when to identify a fraudulent claim as well as how to identify one. This, of course, adds to the complexity of fraud detection.
Predictive models can help. Customer demographics and behavior patterns play a huge role in identifying potential fraud, waste, and abuse. Predictive modeling establishes a set of rules associated with fraudulent behavior. Effective monitoring identifies increasingly accurate fraudulent patterns. As they’re identified, these patterns are codified via a new set of rules that evolve the model further.
Effective monitoring identifies increasingly accurate fraudulent patterns.
A carrier example
“ABC Insurance” has been investigating suspicious claims within their portfolio and discovered that some of them are fraudulent. They seek to develop and implement an enhanced predictive model that can identify and prevent potential fraud and abuse. Typically, the total number of referred fraudulent cases for carriers is 30-60% below industry benchmark fraud detection rates. (This is across a 5-10 year claims history.) With a data-focused approach, however, carriers can analyze FWA behavior patterns using historical data and sourced customer demographics. Plus, machine learning models get better at detection the longer they’re used. When a carrier combines an existing understanding of FWA drivers – usually via a rules-based approach– together with data assets and data modeling expertise, FWA identification (flagging) can improve 3-4 times, with immediate confirmed fraud cases increasing 2-3 times as well.
Handling imbalanced data
A common challenge for insurers is an imbalance in fraudulent claims (i.e., not enough confirmed fraudulent cases to achieve the preferred sample size). Fewer fraudulent claims results in lower confidence in a model’s estimates, due to “low sample size bias.”
It’s also difficult for machine learning models to learn the characteristics of examples from a smaller FWA population, and to differentiate these fraudulent examples from the overall claimant population. The abundance of examples from the majority class can swamp the minority class. Resampling techniques, however, can appropriately overcome the imbalance.
Modeling
Building the perfect model is as much an art as it is a science. EXL data scientists have years of academic and practical experience dealing with various modeling techniques, especially those with imbalanced data. The key is our ability to effectively leverage each of these techniques in context – and understand the advantages (and pitfalls) of each. These methods also integrate data extracted from various internal/external sources using Natural Language Programming techniques.
The below graphic provides a high level view of the modeling process:
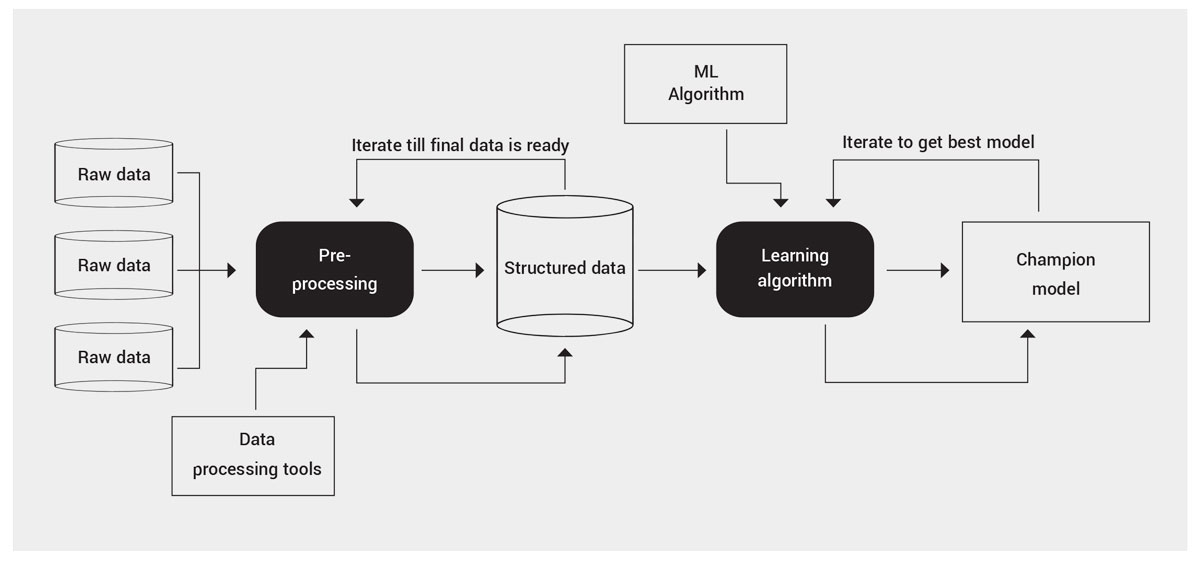
Conclusion
A few key takeaways:
- The financial backbone of an insurance carrier can be irrevocably damaged by fraud, waste, and abuse. FWA is equally harmful to providers, policyholders and, most importantly, taxpayers. In order to improve outcomes for all parties, it’s imperative that FWA is detected in a timely and effective manner.
- Current fraud detection techniques rely heavily on human analysis. While this can be valuable from an experience and common sense standpoint, it’s prone to biases and error, and is limited by available capacity. While experienced specialists provide value to an organization, predictive mechanisms using data-driven techniques are proven more effective in the long run. This is especially true when incorporating the learnings of tenured specialists.
- While machine learning models are complex, their results are invaluable to experienced business specialists. Once built, the models can be managed by existing staff, limiting client-side data and IT support to data provision and light scripting.
Over the years, EXL’s expertise in building and delivering machine learning models to identify fraudulent customers has saved insurance carriers millions of dollars. Not only do these models provide insight into what has occurred, they allow carriers to predict events before they happen. Once these models adapt to a business problem and have a robust monitoring infrastructure in place, they serve as a solid foundation to effectively manage fraud, waste, and abuse.
EXL uses the following approach to combat fraud:
- Discover: We perform a deep dive analysis on documentation files, regulations, taxonomy of product and data. We do this to understand a customer’s product terminology and to prepare a data package in advance of mobilization. We also assess the current state of fraud detection models to get a detailed understanding of the client’s definition of fraud.
- Design: With a solid background obtained from the Discover phase, we design a tailored solution that best fits stakeholder necessities. This involves performing exploratory data analysis, assessing model assumptions and feature engineering.
- Development: With a high level detailed architecture solution, EXL bridges the gap between the desired product as an idea and the product as a concrete, concise and defined object. We develop multiple models in this step before arriving at the champion.
- Testing: We heavily stress test our models to ensure they’re robust. We work with the stakeholder to investigate cases predicted as fraud by the model. It is important that we understand our model performance from both an analytics and operational perspective, to minimize false positives as much as possible. This prevents the natural degradation of the model over time.
- Deployment: While testing is done on a smaller scale, deployment is done on a massive scale, solving production issues that may not have appeared in the smaller sample testing phase. In this phase, the model goes live. We streamline the process to avoid unnecessary BAU impacts.
With machine learning, a solid framework and a hypothesis-led approach allows us to explore multiple avenues of fraud prevention. These techniques, coupled with a carrier’s customer understanding, leads us to novel solutions, improved fraud detection and, ultimately, lower indemnity costs attributed to fraud, waste, and abuse.
References
2. https://www.aaltci.org/long-term-care-insurance/learning-center/
4. https://www.fraud-magazine.com/article.aspx?id=4294967862
Written by:
Karl Canty
Vice President, Analytics
Subha Datta
Senior Program Manager