
Insights for enterprises on harnessing the power of advanced data retrieval
Introduction: The groundwork of generative AI in the enterprise
As generative AI evolves, the spotlight turns to retrieval-augmented generation (RAG) — a sophisticated orchestration of data retrieval and language generation, which is the foundation for the most advanced enterprise AI applications. The efficacy of RAG, however, is contingent on its ability to access and interpret the right data at the right time. This article dissects the essential elements of effective RAG, focusing on vector databases (vector DBs) and knowledge graphs, the unsung heroes of data retrieval.
The primacy of data retrieval in RAG
The journey from vast amounts of data to an insightful response in RAG architectures is critically dependent on the initial retrieval phase. Efficient pre-processing and robust retrieval mechanisms are the backbone of a system that can determine the relevance and accuracy of information before passing it to large language models (LLMs) for augmentation.
Vector databases: Encoding meaning into mathematics
Vectorization explained: Vectorization is a critical first step in data pre-processing, converting text data into a mathematical representation. Language models such as BERT perform complex calculations to transform words, sentences, or documents into vectors, each consisting of hundreds of dimensions. These dimensions capture the context and meaning of language. Embedders come in different varieties depending on the end users consumption preferences – word, paragraph, specialized, multi-lingual, industry-specific, large-scale, etc.
Vector DBs in RAG: Vector DBs are adept at storing high-dimensional vectors and performing semantic searches with blistering speed. In situations that require immediate data retrieval, such as powering a customer service chatbot, vector DBs shine. They quickly find the nearest vector match to a query while ensuring relevancy and accuracy.
Vector DBs for claims queries

Knowledge graphs: Weaving a web of data relationships
Understanding knowledge graphs: Knowledge graphs take a different approach. They excel in their ability to represent and query relationships and connections within and between various data sets, offering a semantic, interconnected map of information, which enables the extraction of more meaningful insights from complex data sets.
Knowledge graphs serve as a method for structuring information systematically, enabling easy comprehension. Comprised of nodes that denote entities such as individuals, locations, and objects, and edges representing connections between these nodes, they offer a means to depict intricate, interlinked data without rigid pre-established frameworks. This flexibility empowers enhanced search functionalities, analytical prowess, and the capacity to draw insights from the data.
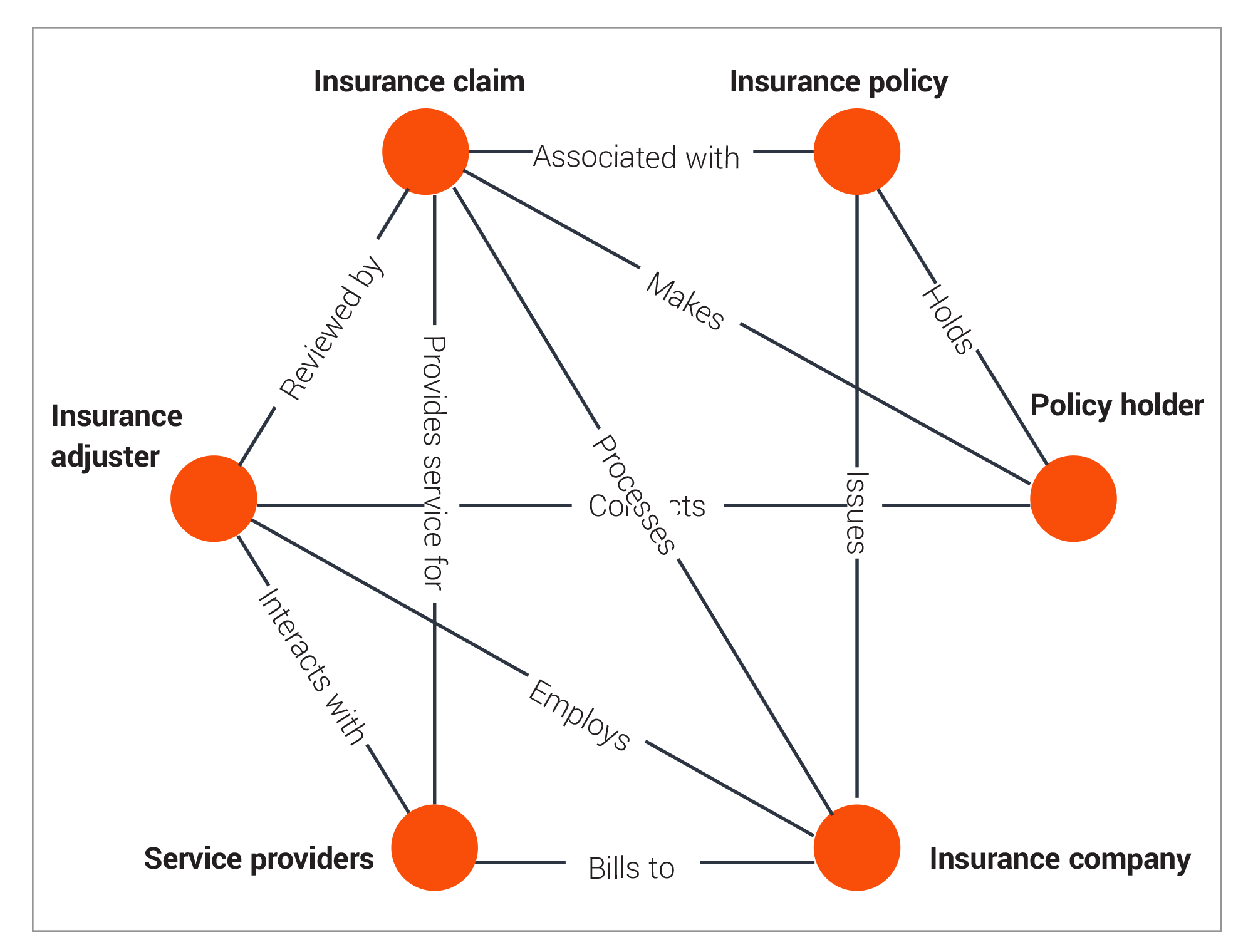
Insurance claim Knowledge graph
Knowledge graphs in RAG: In the context of RAG, knowledge graphs are indispensable when the search is for more than a single data point and instead seeks to understand its context and relationship to other data — the bigger picture rather than a single fact. Knowledge graphs follow the semantic triple model, which is a sequence of three entities that encode information about the meaning of data into the format of subject–predicate– object expressions. E.g., “Mike is 35” or “Mike knows Tom” thus allowing a robust tracing mechanism and fidelity of data during RAG. For an insurance company searching through millions of documents, knowledge graphs enable a RAG system to navigate complex, multi-hop queries.
Vector DBs vs. knowledge graphs in RAG: Suitability over superiority
The choice between vector DBs or knowledge graphs is not binary but rather a matter of fit for purpose based on specific requirements, data characteristics, and use case of the organization.
Vector databases are optimized for similarity search. They can be used to find documents that are similar to a given query document or similar to a given query entity. This makes vector databases well-suited for applications such as document search, image search, and product recommendations.
However, knowledge graphs are optimized for reasoning and inference. They can be used to answer complex questions about data by ingesting data, extracting entities and the relationships within, and then traversing those relationships. They are also well-suited for applications such as question answering, entity linking, link prediction, and knowledge discovery.
In some cases, vector DBs can be used in conjunction with semantic search and knowledge graphs to improve search results.
Illustrative example:
In an ecommerce setting, personalization and relevance are key to improving customer satisfaction and sales. A RAG system can enhance product recommendation engines by retrieving product information, user reviews, and customer queries from a vector DB that has been optimized for similarity search at scale. This approach provides speed, scalability, and agility.
On the other hand, they can use knowledge graphs to represent products, their attributes, user preferences, and past purchasing history. The RAG system utilizes this structured data to understand context and generate recommendations that are not solely based on similarity but also on the intricate relationships and rules encoded in the graph. This approach provides rich context and explainability. Practical Application: For enterprises, the decision hinges on the nature of the task at hand. Is the RAG system answering simple queries or engaging in complex problem-solving that requires traversing a dense web of data?
Typically, companies with a focus on enhancing the customer experience tend to favor speed to market with vector DBs, whereas the ones with a focus on strategic planning and decision support systems lean toward the contextual richness provided by knowledge graphs.
Top five key considerations for making the choice:
- Go for vector DB when your primary need is fast retrieval from within high volumes of unstructured data.
- If there are complex relationships and dependencies between entities of your data, knowledge graphs can capture that.
- Employ knowledge graphs for complex queries requiring rich contextual understanding but anticipate greater resource investment for scalability.
- Managing vector DBs requires minimal technical overhead, making them suitable for organizations looking for straightforward maintenance.
- Prepare for higher initial and ongoing costs with knowledge graphs, which are justified by the strategic depth they add.
- Future-proof your data retrieval strategy with vector DBs for their evolving AI synergy, and knowledge graphs for advancing semantic and reasoning capabilities.
Operationalizing vector DBs and knowledge graphs recommendations:
- Assess your data: Understand the nature of your data. Is it mostly unstructured text? Or is it rich with interrelated concepts and entities? This assessment will guide your choice.
- Define your use case: Clearly articulate the problem you are solving. Vector DBs might suffice for simple FAQ retrieval, but for complex decision-making, knowledge graphs could be essential.
- Consider scalability: Both technologies must scale with your data. Ensure your infrastructure can handle the increasing size and complexity of vectors or the expanding web of your knowledge graph.
- Invest in talent: The technology is only as good as the team behind it. Invest in data scientists and engineers who can tailor these systems to your needs.
- Monitor and iterate: Both vector DBs and knowledge graphs require ongoing tuning to stay effective. Regularly review their performance and iterate as needed.
Vector DBs and knowledge graphs are not just tools but foundational elements that, when appropriately leveraged, can significantly enhance the capabilities of RAG systems.
Conclusion: The art of choosing and using RAG’s data retrieval pillars
Data preprocessing is the linchpin of RAG success. Vector DBs and knowledge graphs are not just tools but foundational elements that, when appropriately leveraged, can significantly enhance the capabilities of RAG systems. Enterprises must carefully consider their organization’s unique needs, data complexity, and the desired outcomes to make the most of these powerful technologies. As we champion the growth of generative AI, let’s not forget the critical role of these unsung heroes in our RAG narratives.
Written by:
Anand Logani
Chief Digital Officer
Anupam Kumar
Vice President - Senior AI Architect