Meta data driven approach to data lakes – avoiding a data swamp!

While data modernisation projects offer numerous advantages to a business by enabling greater access to data insights that can drive business benefits, they are still fraught with development issues. Any solution that ingests vast amounts of that data needs to be architected and developed correctly, otherwise they will struggle to deliver value. A primary challenge in building a Data Lake is being able to ingest the data required in a timely and cost-effective manner. Equally, new and evolving requirements around data privacy and the protection of Personally Identifying Information (PII) data, drives the need for a robust process to handle data and ensure that appropriate measures are applied consistently, particularly as the data sources expand. Taking a brute force approach to bringing data into a lake may lead to ballooning costs and could lead to ongoing development issues that will be difficult to rectify.
This paper highlights the data modernisation journey of a leading personal lines insurer and the differentiated approach adopted that helped in minimising the amount of coding in building a cloud hosted Data Lake; while ensuring that all the relevant security, auditing and privacy requirements were robustly managed.
Background
Ageas UK is one of the largest general insurers in the United Kingdom, providing insurance to over five million customers. It offers car, home, pet, and small business insurance through brokers, affinity partners and its own brands.
Insurance, in a way, has always been data driven so it is somewhat of a surprise when you consider it is not one of the first sectors to really embrace data modernisation to its full potential. There can be a general lack of purpose to large amounts of data generated and therefore a large amount of value can be left on the table.
Ageas UK identified this opportunity and initiated a significant data modernisation programme to unlock the full potential of its data. Ageas UK understood that by proactively driving the transformation to become a modern, data driven organisation, it could deliver on new opportunities and innovation, whilst meeting the expectations of its customers and regulators.
A centralised data function was created, and it set about realising the benefits offered by ‘doing more’ with its data. The first step of this transformation centred on the implementation of a Data Lake, bringing together a volume and variety of data that had never been seen before by Ageas UK, and making it available to the business, which in turn unlocked new insights and analysis.
Ageas UK collaborated with EXL to embark on this journey to enable and deliver modern data platforms while working towards delivering an industry-leading data organisation that is future-proof and provides relevant opportunities to unlock value and insights.
Our capabilities and services changed, almost overnight. Data that had previously been unavailable to the business was now in our hands. Technical limitations were removed. Performance and trust became the standard. New opportunities revealed themselves.
As the engine room of our service, the Data Lake will be an enabler for business growth. We have no doubt that our data platform will continue to evolve over time, but what is clear is that our ability to integrate and expose data, at pace, is already creating new value for the business.
 Matt Smith –
Matt Smith –
Head of Enterprise Data,
Ageas UK
What were the benefits of building a Data Lake?
As business data (both structured and unstructured) grows at unprecedented rates and access to this data is crucial to unlock analytical use cases, building a Data Lake is considered a foundation of a modern data program. The benefits of building a Data Lake included:
- The ability to combine structured data from a variety of sources such as CRM systems, social media analytics, buying history from operational systems, customer profiling data and web analytics from digital platforms. These can provide an enhanced understanding of customers, operations and performance.
- Versatility. A Data Lake allows the combination of multiple data sources and types. Traditional structured data, streamed event data, unstructured data (documents, images etc.) can all be loaded into a single platform.
- A test platform for new product designs, profitability or risk modelling, pricing models etc.
- Improved analysis of operational efficiencies and post-sale support through Internet of Things (IoT) data. Modelling of claims/risk profiles through IoT data matched with claims histories and policy data.
- Advanced analytics. Allowing access to the vast and diverse dataset(s) is crucial to unlocking many many analytical opportunities previously unavailable to businesses.
- Consolidation of data sources into a single area that can be accessed by chosen computer engines (e.g. Spark, Hadoop, U-SQL etc.). Act as a single source of the organisation’s data.
For example, the data spread across quote, policy, claims, telephony and marketing databases, can use a Data Lake to bring this information together. The lake allowed Ageas UK to combine the voluminous data from quote systems (where terabytes of data per day can be generated) with policy and claims data to enable more in-depth analytics to be generated than previously possible.
The pitfalls of building a Data Lake
In theory the inherent flexibility of a Data Lake project should allow a faster time to market and a lower development cost for traditional data solutions i.e. building a data warehouse. However, Data Lake projects can suffer from cost overruns, delays and a failure to derive value. Some of the reasons for this are outlined below:
- The business requirement- Data Lakes need to exist for a purpose and that purpose needs to be matched with business needs otherwise this leads to issues with data selection and prioritisation, data security and access etc.
- Being overwhelmed by data- The purpose of a Data Lake is to gather as much organisational data as possible. However, this can be an endless task as the number and volumes of sources overwhelms a business’ development team’s capacity to build the required code artefacts.
- A lack of engineering skills- Most Data Lakes today suffer from poor design and implementation. The shortage of software engineering talent combined with the lack of relevant technology experience is one of the root causes. A lack of engineering skills often leads to Data Lake implementations with poor architectural design, poor integration, poor scalability, and poor testability – all of which can lead to poor outcomes and usage.
- Missing foundational capabilities- There is a general tendency to underestimate the complexity of Data Lake solutions from an architectural, technical, and engineering perspective. Every Data Lake should expose a good number of technical capabilities, some of these are data ingest, data preparation, data profiling, data classification, data governance, data lineage, metadata management, security and logging. A robust framework is needed to ensure that these complex non-functional requirements are met without impeding delivery of value. If this is perceived to be the case, it can lead to short cuts being taken which will eventually comprise the value of the solution.
- Poor data oversight- During the initial phase of any Data Lake implementation, there is often not enough focus on how to organise and control data. Given data is to be accessed by multiple users through several applications, governance is essential to build trusted solutions where data quality and accountability both play an important role. Building a business glossary and metadata repository needs to go handin-hand with loading data into the lake. However, a governance model is not enough. Data security, protection, government regulation etc. also need to be considered.
- Privacy and security- The original approach of simply replicating the source data model when ingesting data is not sustainable when considering privacy regulations such as General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA). GDPR for example, has specific requirements regarding retention, minimisation and metadata. That comes with the possibility of significant financial impact if these are broken. Given the reputational risk that comes from breaches in data security, it is critical that any lake solution has a robust security implementation and process for managing privacy requirements. Data democratisation must be matched with the responsible management of data.
All these issues can lead to what is colloquially know as an organisation’s Data Lake turning in a ‘data swamp’. This is where an organisation fails to derive the benefit from building a lake. It is incomplete, cannot be navigated, users are restricted in their use due to security or privacy risk, or they experience poor performance due to architectural issues. Avoiding these issues and maximising the value of Ageas UK investment in a data Lake was critical to a successful delivery. The paper outlines how this was achieved.
Data Lake architecture considerations
As the above outlines, there are many challenges that can derail a Data Lake project. If we drill into some of the technical issues, we can highlight the specific issues that need to be considered.
Data volume
Data Lakes are characterised by their volume both in the amount of data (terabytes, petabytes etc.) and the number of objects within it. From a typical source system there can be hundreds or even thousands of objects that need to be ingested. To move past the puddle, pond and into a fully-fledged lake, this data ingestion process needs to be repeated for multiple source systems to allow the number of objects in the lake to grow precipitously.
The sheer number of objects that need to be loaded can overwhelm the development team, either leading to increased costs as a result of team expansion or failure to reap the benefits of building a lake by not consuming sources fast enough to match the requirements of the business. Another risk is that due to the volume of work required, shortcuts are often taken that are difficult to detect and costly to rectify when discovered.
Data Lake Zones
Most Data Lakes are spilt into zones that allow for data to be augmented, partitioned and tagged per requirement. There are several possibilities. This is a typical configuration:
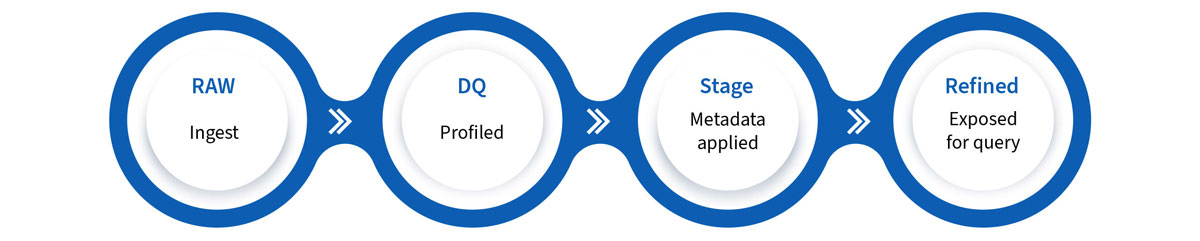
However, as privacy regulations drive the need for transparent control of PII elements coupled with other requirements such as legal entity separation, this can lead to a more complicated design.
How a metadata driven approach can accelerate development
As with any Enterprise Data Management (EDM) project, a well-structured Data Lake requires a robust development approach and methodology. At EXL, our approach is encapsulated in our Intelligent Data Factory (IDF) methodology.
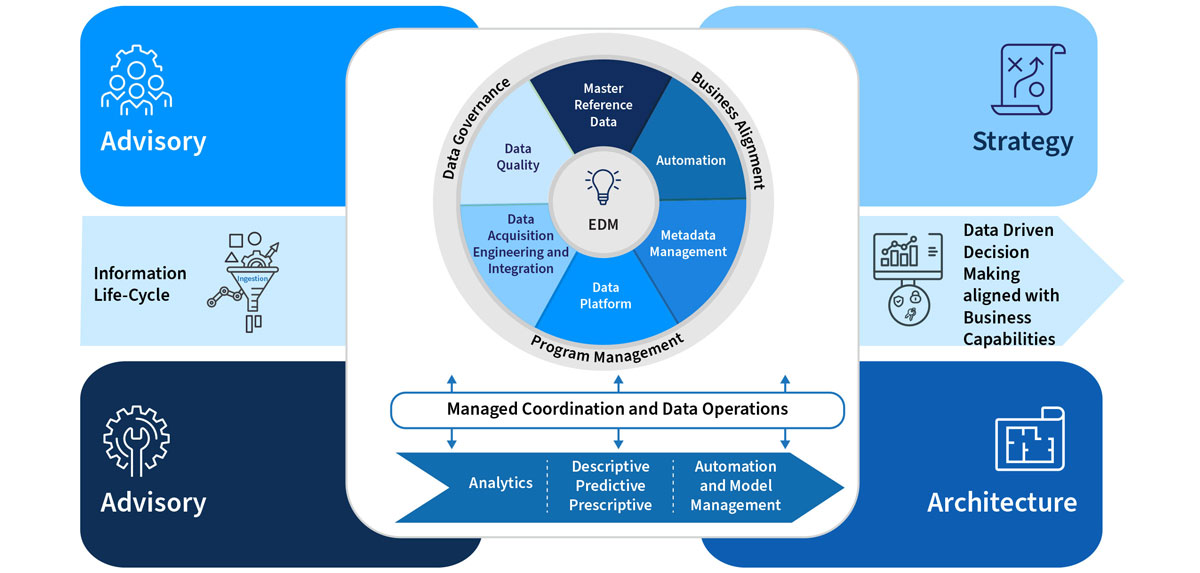
IDF couples best-in-class EDM capabilities with analytics excellence. These are aligned to corporate business goals with a focus on cost-effectiveness, risk reduction and program longevity. A core component of IDF is to ensure that the architecture and implementation typically leads to the use of the EXL data engineering framework.
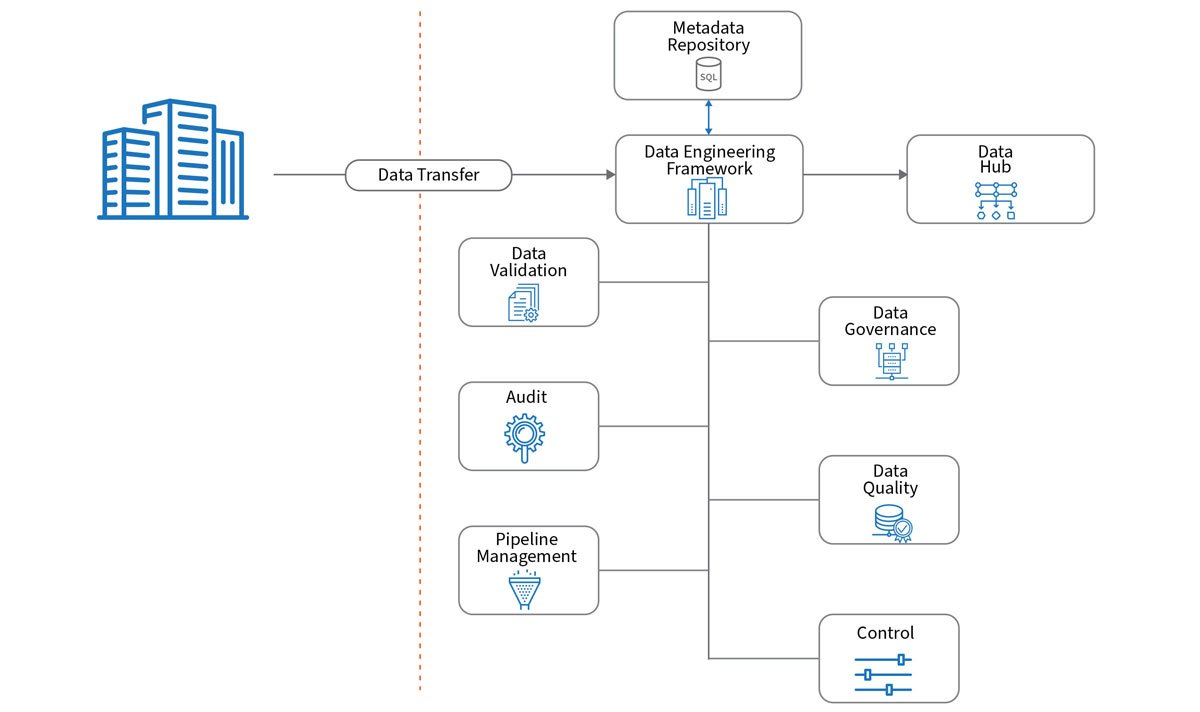
The data engineering framework is made up of a set of reusable modules. New modules can be added anytime. This design removes the interdependency between functional modules, increases reusability and allows simpler recoverability in the event of failure.
A core component of the framework is metadata repository. This contains the following components:
- Sources- These need to be captured and will supply data to the platform. This will include details such as their name, type and connection details.
- Entities- There are entities for each source, where the details of each source will be stored. Metadata contained here includes the name, type, structure, location details and sequence. In addition to this, extra computed, defaults and calculated columns are stored. These will be required where the input structure doesn’t match the output and additional columns need to be created and populated.
- Phases- These are the foundation of the data ingestion pipeline and should be used to tie together the activities of data processing. The number of phases is configurable based on the number of zones the data needs to be moved through and the requirements.
- Processing- This activity refers to the processing of data within or onto the next phase of the data ingestion pipeline. They form activities, with a priority attached.
- Maintenance- All Data Lakes require maintenance activities to take place such as compaction or reorganisation of files in order to maintain performance. This also includes items such as data retention and regulatory compliance, for example GDPR, where personal data is required to be purged/redacted from the data after it has reached its agreed retention. Structuring the lake in such a way to make this achievable is an important design consideration when developing how the data is organised in the Data Lake zones.
An example of the process can be seen below:
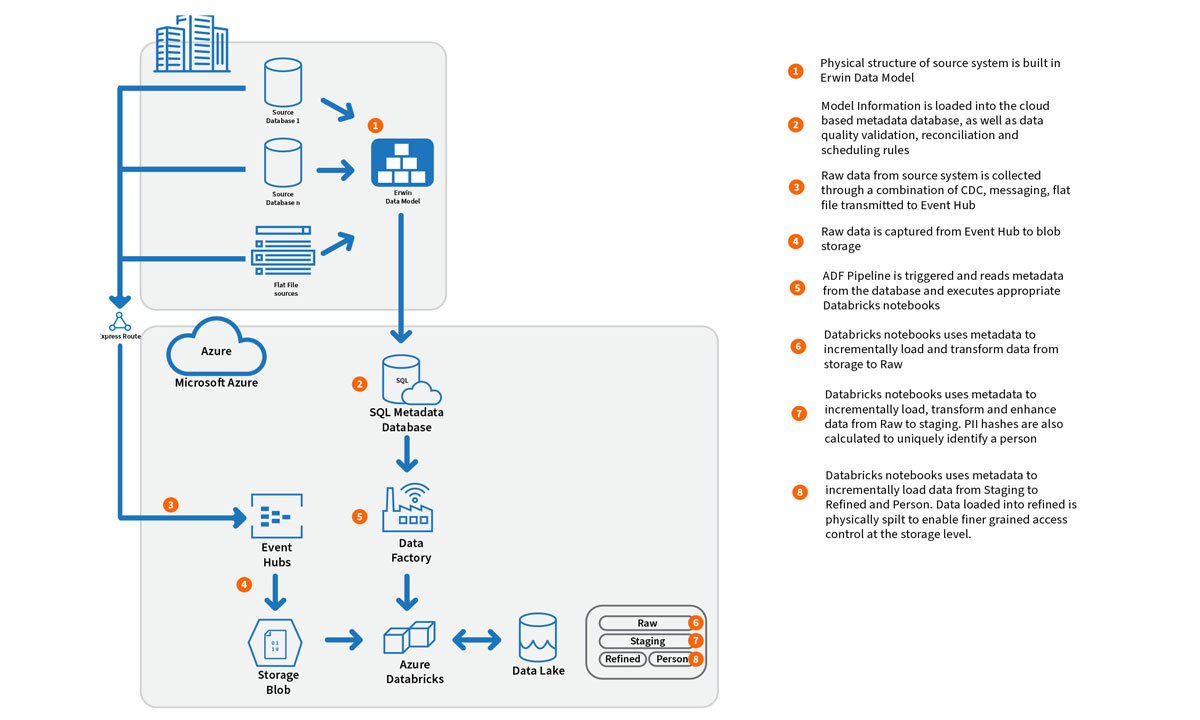
Combining this metadata with the pipeline management component allows the solution to be scaled quickly to accommodate data sources without additional components. An example can be seen below where the reader can see the difference between the number of objects loaded into a Data Lake by source and the number of Extract Transform and Load (ETL) Databricks notebooks required to load it. There are far fewer core notebooks then the number of objects to be loaded required to handle the core load, audit, control, security and PII functions. For each additional data source, a small number of extra notebooks are required to handle the initial ingestion.
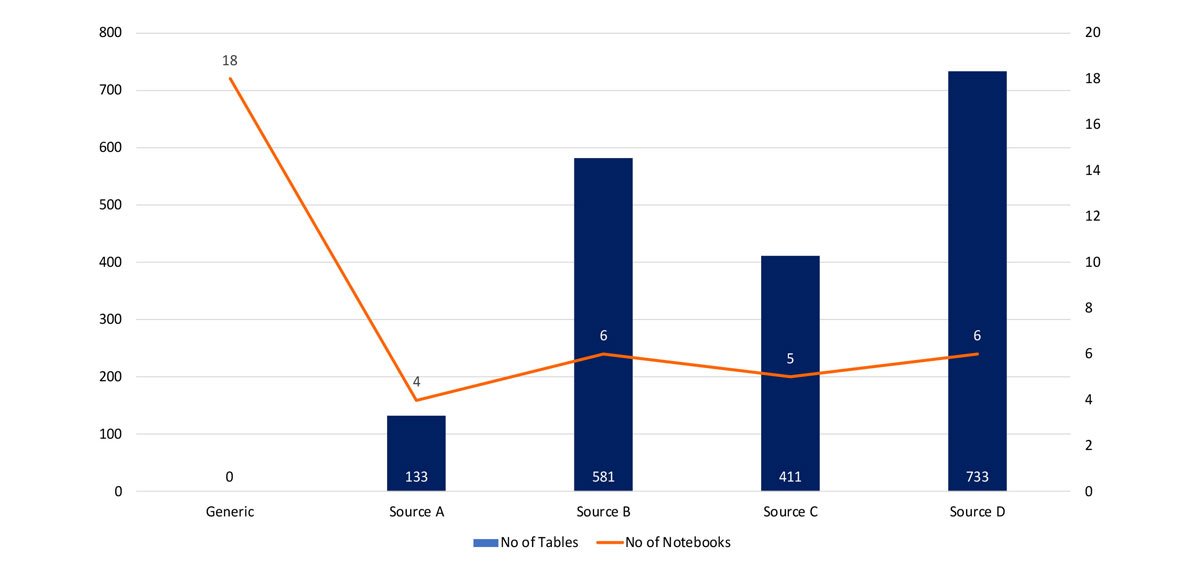
As each supplementary source only requires small additional effort, the number of data sources that the lake can consume can be quickly scaled without increasing the development team to an unmanageable level. Also, the core functionality is contained within a common set of notebooks, ensuring that critical requirements such as GDPR, PII data separation, security and auditing is uniform across all data sources minimising the risk of defects and compliance issues as more data sources are loaded into the lake.
This shows that once the initial work is completed, the effort to load an additional resource is greatly reduced. Each additional resource could take a team of several developers to load into the lake but we can see from above that it can be achieved with a much smaller number to build the small set of source specific notebooks.
Based on a real world example, comparing load data through the Data Lake using a notebook per table against the metadata driven approach, it is estimated that there is a 50% saving in effort using this metadata driven approach. This also results in an extremely low number of defects overall, as there is very little or no code change required. This feeds into the ongoing maintenance of the lake as the additional changes require much less testing as they rely on the robustly tested cored framework.
Conclusion
Ageas UK and EXL’s impetus for a metadata driven approach ensured that critical requirements were delivered in a consistent, repeatable, secure and costeffective manner. Taking this approach to building a Data Lake addressed many of the pitfalls and helped in achieving the project objectives while maximising benefits missing from a more traditional development approach.
These include:
- Being overwhelmed by data- Taking this approach allows a team to handle many more data sources in parallel than otherwise possible.
- A lack of engineering skills- The core advantage of this solution allows for all the complexity to be concentrated into a core set of objects that are reused. This lowers the number of resources and skills required to maintain and enhance the system. It also allows the scaling of the solution to be managed easily as the core code can be designed to scale, meeting the data volume needs and rigorous testing can ensure that this is achieved.
- Missing foundational capabilities- The use of a robust framework that is rigorously applied to all packages and data ensures that all the audit and control requirements are satisfied in a consistent manner.
- Privacy and security- This approach ensures that all data is loaded in a manner that enforces all privacy and security rules. It minimizes the risk of data leakage while allowing the lake to be accessed by a wide variety of users.
The Data Lake project for Ageas UK, mentioned previously in this whitepaper, demonstrates the significant impact of this approach. The team was able to achieve the following benefits following the project:
Data Volume
Loaded 8.7 billion quotes at an approximate rate of 7.5 billion rows per hour. This spanned 728 objects in a Data Lake with 23,000 + attributes. All of this was accomplished with only 47 stored procedures and 35 Databricks notebooks. In other words, the metadata-driven approach scales very effectively with the underlying architecture.
Engineering
With a more traditional approach, the team would have produced at least 728 pieces of code. With the metadatadriven approach, the team produced only 82 pieces of code. Ultimately, this results in supporting roughly 11% of the code that would be required from a more traditional approach. In addition, with a metadata-driven solution, the code is more uniform, which ultimately reduces the support effort.
Privacy and security
By reducing the variability in the code created, the metadata-driven approach reduces the chances of inadvertent security gaps that may be opened with manual coding of 728 code objects. As an example, if certain data protection or privacy standards are required (e.g. GDPR or CCPA), management of that data is programmed once and then re-used throughout the solution in a consistent manner.
Cost-Effective
As stated above, the team ended up having to generate approximately 11% of the code objects that would be required of a more traditional approach. Although it doesn’t directly equate to 11% of the effort (because some of the code can be more sophisticated), we were able to drive a significant reduction in development effort.
As a case in point, the development hours on the same project in the same environment, prior to implementing the metadata driven approach, was approximately fiveman years for two different data sources.
For a third similarly sized data source, the development effort is approximately five-man months. This equates to a reduction of 45% to 55% in development effort. Although anecdotal, the above scenario is similar to what we have seen with other projects. There is an additional benefit as the reuse of code reduces additional future testing effort of future data deliveries to the lake as the core code and metadata approach had already been tested. This allows for further sources to be loaded into lake at an increased velocity than would be otherwise possible.
A Data Lake is a critical component to unlocking the value of data within an organisation. The solution laid out above allowed Ageas UK to unlock several analytic use cases that previously were not possible due to infrastructure capacity and delivery capabilities. Working in partnership with EXL ensured that the Data Lake was delivered within defined timelines and generating immediate value while allowing for growth in a scalable, cost effective manner.
Written by
Kshitij Jain
Head of Analytics
UK and Europe Sanjay Nayyar
VP Enterprise Data
Management UK and Europe
Contributors
Mark Collins
Chief Information Officer,
Ageas UK Matt Smith
Head of Enterprise Data,
Ageas UK